















| Data Center Max 1100 | Data Center Max 1350 | Data Center Max 1550 | AMD Instinct MI250X | Nvidia H100 | Nvidia H100 | Rialto Bridge | |
| Form-Factor | PCIe | OAM | OAM | OAM | SXM | PCIe | OAM |
| Tiles + Memory | ? | ? | 39+8 | 2+8 | 1+6 | 1+6 | many |
| Transistors | ? | ? | 100 billion | 58 billion | 80 billion | 80 billion | loads of them |
| Xe HPC Cores | Compute Units | 56 | 112 | 128 | 220 | 132 | 114 | 160 Enhanced Xe HPC Cores |
| RT Cores | 56 | 112 | 128 | - | - | - | ? |
| 512-bit Vector Engines | 448 | 896 | 1024 | ? | ? | ? | ? |
| 4096-bit Matrix Engines | 448 | 896 | 1024 | ? | ? | ? | ? |
| L1 Cache | ? | ? | 64MB at 105 TB/s | ? | ? | ? | ? |
| L2 Rambo Cache | ? | ? | 408MB at 13 TB/s | ? | 50MB | 50MB | ? |
| HBM2E | 48GB | 96GB | 128GB at 3.2 TB/s | 128 GB/s at 3.2 TB/s | 80GB at 3.35 TB/s | 8GB at 2 TB/s | ? |
| Multi-GPU IO | 8 | 16 | 16 | 8 | 8 | 8 | ? |
| Power | 300W | 450W | 600W | 560W | 700W | 350W | 800W |
| Data Center Max 1550 | AMD Instinct MI250X | Nvidia H100 | Nvidia H100 | |
| Form-Factor | OAM | OAM | SXM | PCIe |
| HBM2E | 128GB at 3.2 TB/s | 128 GB/s at 3.2 TB/s | 80GB at 3.35 TB/s | 80GB at 2 TB/s |
| Power | 600W | 560W | 700W | 350W |
| Peak INT8 Vector | ? | 383 TOPS | 133.8 TFLOPS | 102.4 TFLOPS |
| Peak FP16 Vector | 104 TFLOPS | 383 TFLOPS | 134 TFLOPS | 102.4 TFLOPS |
| Peak BF16 Vector | ? | 383 TFLOPS | 133.8 TFLOPS | 102.4 TFLOPS |
| Peak FP32 Vector | 52 TFLOPS | 47.9 TFLOPS | 67 TFLOPS | 51 TFLOPS |
| Peak FP64 Vector | 52 TFLOPS | 47.9 TFLOPS | 34 TFLOPS | 26 TFLOPS |
| Peak INT8 Tensor | 1678 TOPS | ? | 1979 TOPS | 3958 TOPS* | 1513 TOPS | 3026 TOPS* |
| Peak FP16 Tensor | 839 TFLOPS | ? | 989 TFLOPS | 1979 TFLOPS* | 756 TFLOPS | 1513 TFLOPS* |
| Peak BF16 Tensor | 839 TFLOPS | ? | 989 TFLOPS | 1979 TFLOPS* | 756 TFLOPS | 1513 TFLOPS* |
| Peak FP32 Tensor | 419 TFLOPS | 95.7 TFLOPS | 989 TFLOPS | 756 TFLOPS |
| Peak FP64 Tensor | - | 95.7 TFLOPS | 67 TFLOPS | 51 TFLOPS |
인텔은 이전에 코드명이 폰테 베키오였던 데이터 센터용 맥스 GPU 시리즈를 발표하고 출시했습니다.
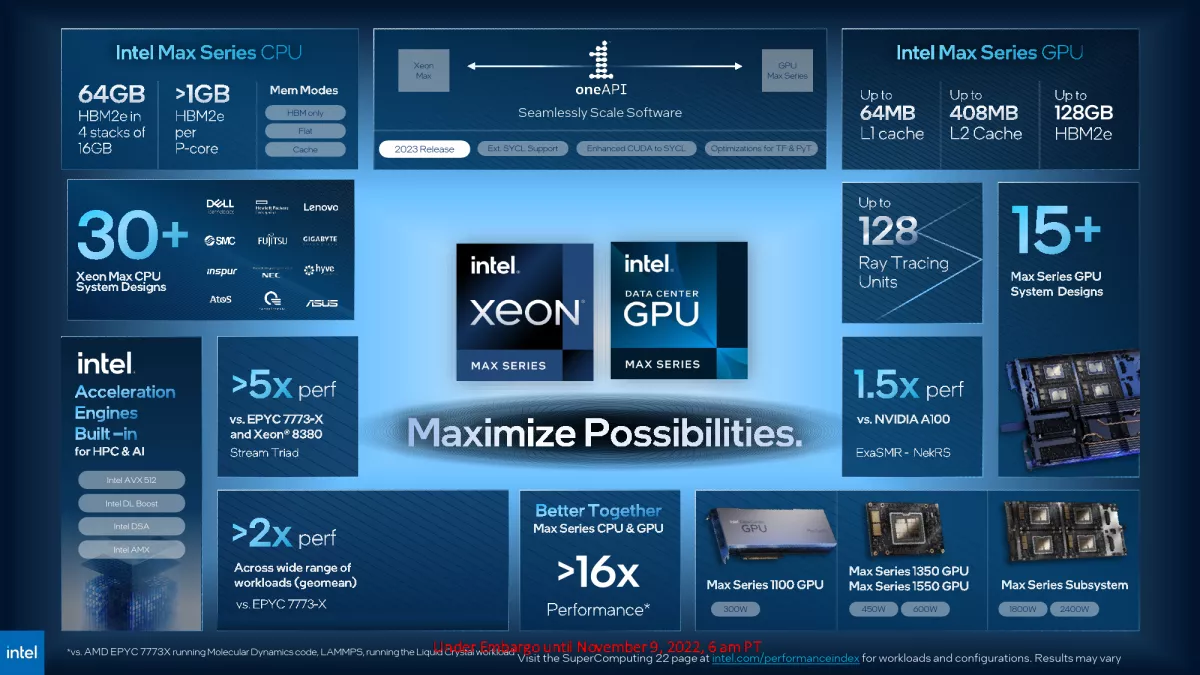
Intel의 Data Center GPU Max 컴퓨팅 GPU는 AI 및 HPC 워크로드에 명시적으로 맞춘 회사의 Xe-HPC 아키텍처에 의존하므로 512비트 벡터 및 4096비트 매트릭스(텐서) 엔진뿐만 아니라 적절한 데이터 형식과 명령을 지원합니다.
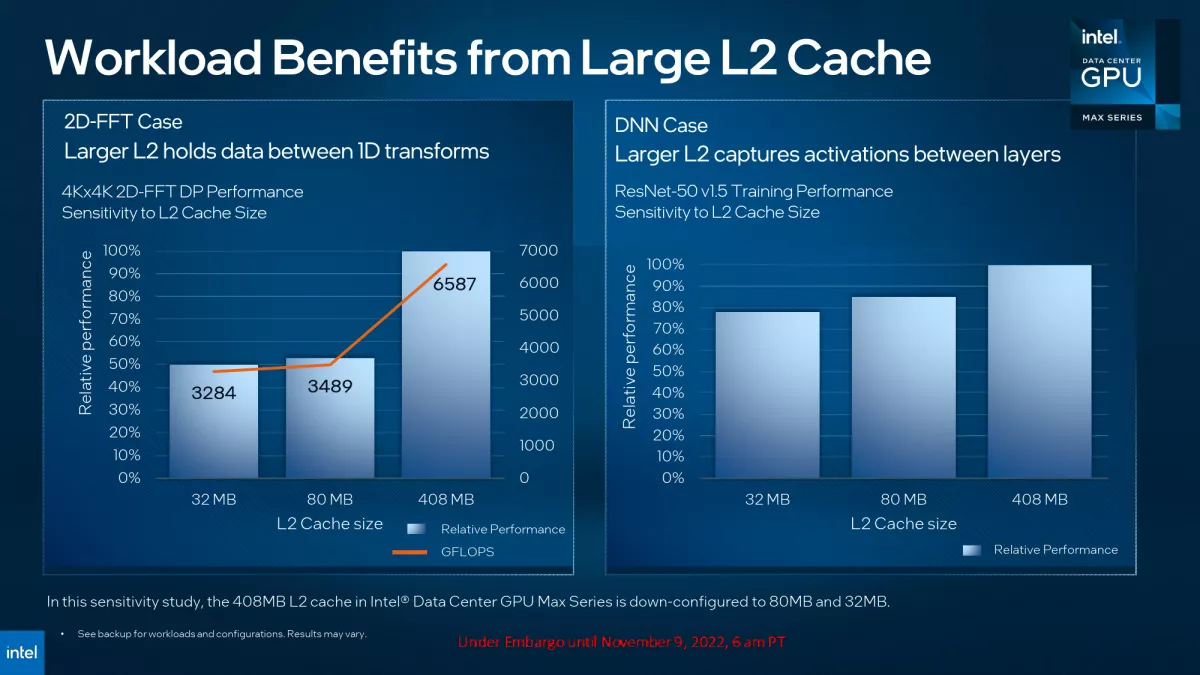
Xe-HPG와 비교하여 Xe-HPC는 훨씬 더 정교한 메모리 및 캐싱 하위 시스템, 서로 다르게 구성된 Xe-HPG 코어는 16개의 256비트 벡터 및 16개의 1024비트 매트릭스 엔진을 갖추고 있으며, 각 Xe-HPC 코어는 8개의 512비트 벡터 및 8개의 4096비트 벡터 엔진을 지원합니다. 또한 Xe-HPC GPU는 텍스처링 유닛이나 렌더 백엔드를 갖추고 있지 않으므로 기존 방식으로는 그래픽을 렌더링할 수 없습니다. 한편, Xe-HPG는 슈퍼컴퓨터 시각화를 위한 광선 추적을 놀랍게도 지원합니다.
Xe-HPC의 가장 중요한 구성 요소 중 하나는 Intel의 Xe Matrix Extensions(XMX)로 Intel의 Data Center GPU Max 1550(아래 표 참조)의 강력한 텐서/매트릭스 성능을 지원합니다(최대 419 TF32 TFLOPS 및 최대 1678 INT8 TOP). 물론 컴퓨팅 GPU 개발자가 제공하는 최대 성능 수치는 중요하지만 실제 애플리케이션의 실제 슈퍼컴퓨터에서 달성할 수 있는 성능을 반영하지 못할 수도 있습니다. 그럼에도 불구하고 Intel의 레인지 톱 Ponte Vecchio는 대부분의 경우 Nvidia의 H100보다 크게 뒤쳐져 있으며 FP32 Tensor(TF32)를 제외한 모든 경우에서 AMD의 Institution MI250X보다 실질적인 이점을 제공하지 못하고 있습니다.
Intel은 데이터 센터 GPU Max 1550이 Nvidia의 A100 on Riskfuel 크레딧 옵션 가격보다 2.4배 빠르며 NekRS 가상 원자로 시뮬레이션의 경우 A100보다 1.5배 향상된 성능을 제공한다고 밝혔습니다.
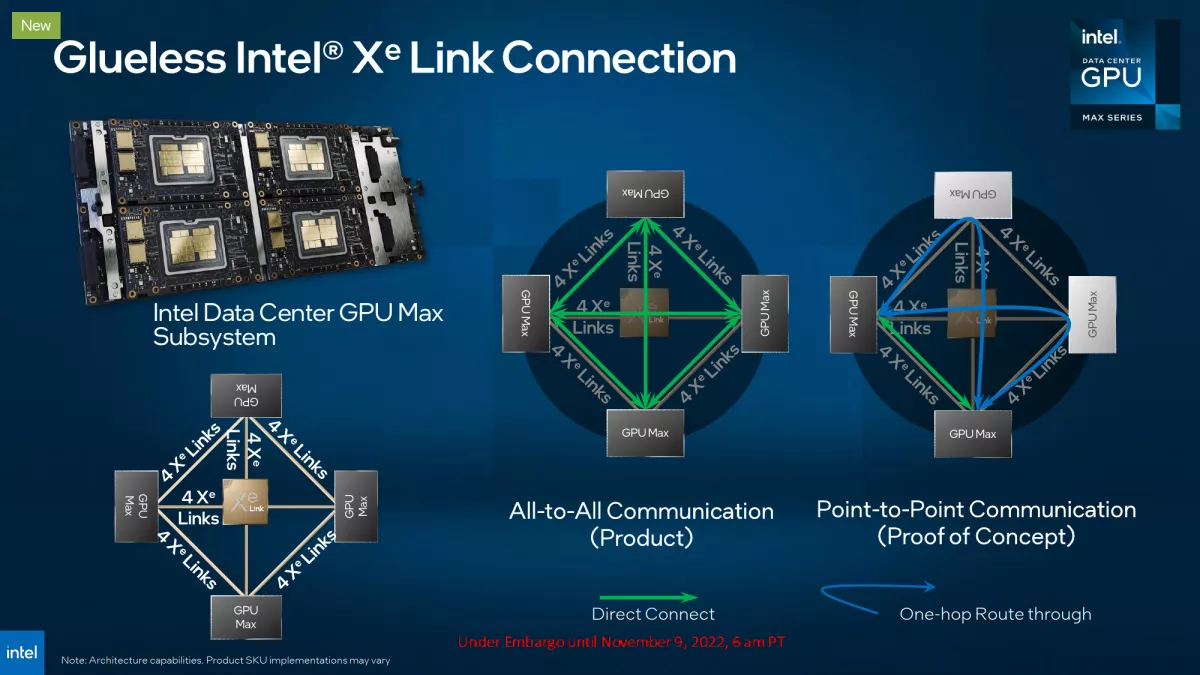
Intel은 3개의 Ponte Vecchio 제품을 제공할 계획입니다. 128개의 Xe-HPC 코어, 128GB의 HBM2E 메모리를 갖춘 OAM 폼 팩터의 최고급 데이터 센터 GPU Max 1550, 112개의 Xe-HPC 코어, 96GB의 메모리 및 450W 엔트리 레벨 데이터 센터 GPU Max 1350 듀얼 와이드 FLFH 폼 팩터로 제공되며 56 Xe-HPC 코어를 갖춘 프로세서를 탑재하고 56GB의 HBM2E 메모리를 탑재하며 300W TDP에 대한 정격을 갖춘 센터 GPU Max 1100입니다.
한편, 인텔은 슈퍼컴퓨터 고객들에게 1,800W와 2,400W TDP의 정격 캐리어 보드에 4개의 OAM 모듈을 갖춘 Max Series Subsystems를 제공할 예정입니다.
'IT 소식' 카테고리의 다른 글
| 삼성 갤럭시 S23 티저 영상 등장 (0) | 2023.01.11 |
|---|---|
| 삼성전자 갤럭시 S23, 새로운 카메라 기능 추가...천체 하이퍼랩스 영상 촬영 (1) | 2023.01.11 |
| 인텔, CPU 제온 맥스 시리즈 출시 (0) | 2023.01.11 |
| 인텔, 4세대 제온 사파이어 래피즈 CPU 출시 (1) | 2023.01.11 |
| 맥북 에어 15인치, 디자인 그대로 냉각 성능 강화...M2 프로 탑재 가능성 (0) | 2023.01.11 |

